















Terraform @ Scale n’est pas une question d’utilisation de l’outil. C’est une question d’Operating Model.
Sans modèle de gouvernance structuré, on obtient :
- des forks de modules non maîtrisés
- des standards de sécurité divergents
- des responsabilités floues
- des risques opérationnels en hausse
- des surfaces d’attaque réglementaires
- un impact financier significatif dû à des mauvaises configurations
Cet article de clôture de notre série décrit de manière synthétique :
- un Terraform Operating Model transversal
- des principes de gouvernance et de structure
- des responsabilités organisationnelles
- l’intégration CI/CD et Policy
- l’agrégation des risques au niveau de l’entreprise
- un blueprint complet pour Terraform @ Scale
Public cible : CIO, CISO, Head of Platform Engineering, Cloud Architects.
Guide opérationnel pour décideurs et architectes
1. Le Terraform Operating Model (architecture de référence)
Terraform ne se met pas à l’échelle avec plus de code. Il se met à l’échelle surtout avec une structure propre.
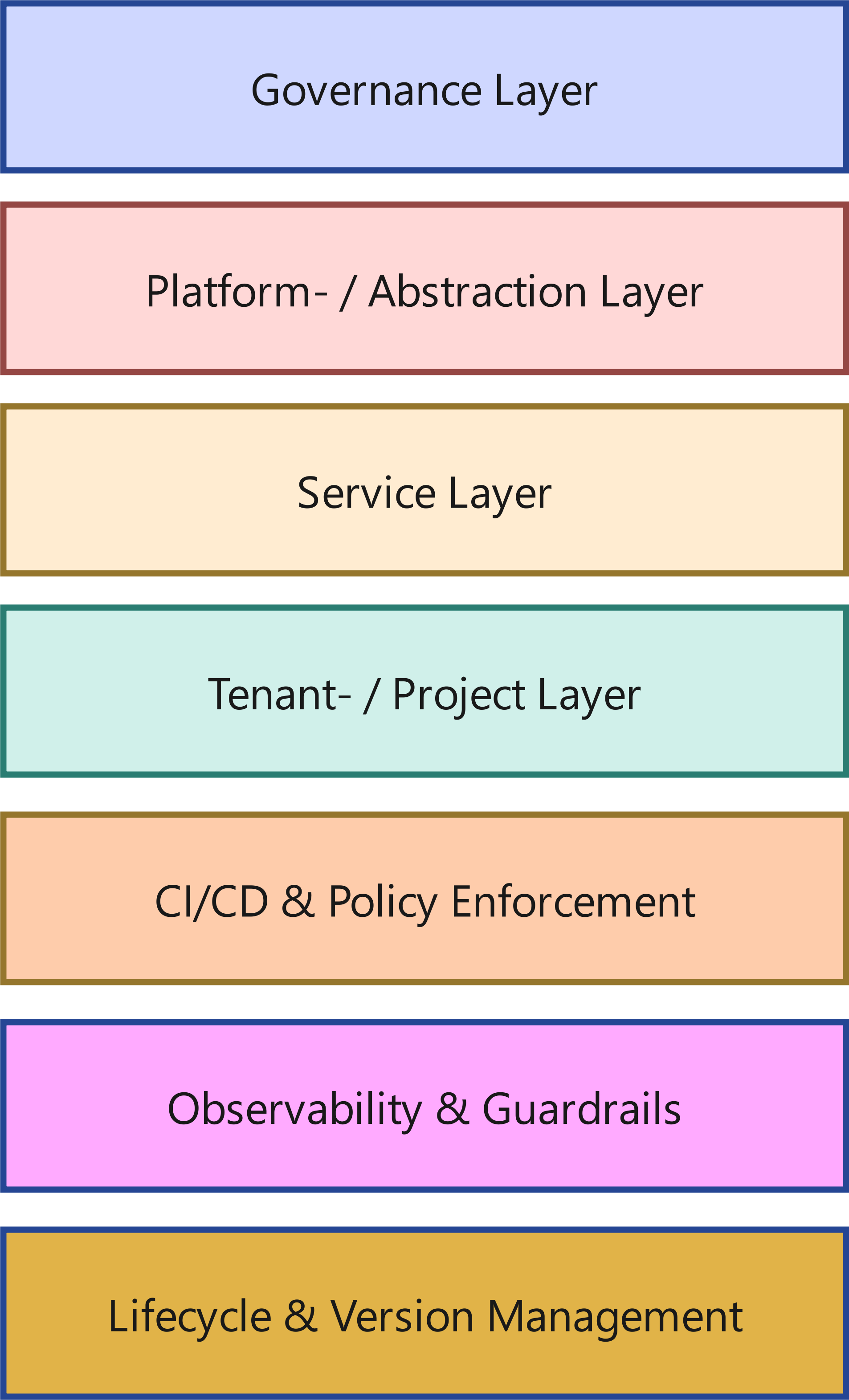 Un Operating Model robuste se compose de couches clairement séparées:
Un Operating Model robuste se compose de couches clairement séparées:
1.1 Couche Governance
- Policy-as-Code (Sentinel, OPA)
- règles de conformité
- standards de nommage
- exigences de sécurité
- mécanismes de contrôle des coûts
1.2 Couche plateforme / abstraction
- modules de base
- standards réseau
- patterns IAM
- fondations Logging - Monitoring
- Security Controls
1.3 Couche service
- modules de service réutilisables
- infrastructure proche de l’application
- patterns base de données
- patterns messaging
1.4 Couche tenant / projet
- configuration produit ou projet
- paramètres spécifiques à l’environnement
- root modules
1.5 CI/CD - Policy Enforcement
- pipelines automatisés
- Mandatory Reviews
- validation du plan
- Policy Checks avant apply
1.6 Observability - Guardrails
- Drift Detection
- monitoring des déploiements
- audit trails
- alerting en cas de violations de Policy
1.7 Lifecycle - gestion des versions
- versioning des modules
- versioning sémantique
- stratégies de dépréciation
- chemins de migration
L’essentiel : ces couches existent volontairement séparées - techniquement comme organisationnellement.
2. Comment orchestrer Terraform à l’échelle de l’entreprise
Terraform en contexte enterprise n’est pas une collection de repositories.
C’est un système orchestré.
2.1 Structure GitOps
Structure recommandée :
- repositories de modules de base
- repositories de modules de service
- repositories d’environnements / root
- repositories de Policy centralisés
Stratégies de branches :
- Protected Main Branches
- Pull-Request Reviews
- version tags pour les releases de production
2.2 Rôles - responsabilités
- équipe plateforme : modules de base - Governance
- équipes produit : modules de service - root modules
- sécurité : définition - review des Policies
- FinOps : contrôle des coûts - reporting
Sans séparation claire des rôles, le chaos s’installe.
Avec une séparation claire des rôles, la scalabilité apparaît.
2.3 Workspaces / Stacks / Environments
- séparation nette entre Dev / Stage / Prod
- aucun switch d’environnement implicite
- aucune manipulation manuelle du state
2.4 Modules de base vs modules de service vs root modules
- modules de base : standards techniques
- modules de service : services réutilisables
- root modules : implémentation concrète
Cette séparation réduit fortement le blast radius.
2.5 Processus de migration
- stratégies d’upgrade de version
- canary deployments
- rollouts par étapes
- regression testing avant propagation
2.6 Processus de review et d’automatisation
- pipelines obligatoires
- Policy Checks
- tests automatisés
- aucun droit d’apply direct en production
3. Blueprint : Terraform @ Scale en pratique
Ce blueprint montre un flux de référence end-to-end qui fonctionne de façon fiable en contexte enterprise : de la modification d’un module jusqu’au rollout audit-able vers plusieurs équipes produit - y compris Governance, testing, propagation et observability.
3.1 Cible en une phrase
L’équipe plateforme livre des modules de base versionnés + des guardrails ; les équipes produit les consomment via des root modules clairement définis ; le CI/CD impose tests, Policy et apply contrôlé ; drift et audit tournent en continu.
3.2 Types de modules - contrats
3.2.1 Modules de base
- définissent des standards techniques (réseau, baseline IAM, logging, encryption defaults)
- peuvent introduire des breaking changes - mais uniquement de façon contrôlée et rarement
- sont SemVer-strict : MAJOR.MINOR.PATCH
3.2.2 Modules de service
- encapsulent des services récurrents
- utilisent des modules de base
- ont des interfaces stables (inputs/outputs)
3.2.3 Root modules
- « Assemblies » : combinent modules de service et modules de base pour un environnement concret
- ne contiennent aucune logique qui devrait se trouver dans des modules
- sont l’endroit où la paramétrisation est spécifique au produit - à l’environnement (les « T-Shirt Sizes » avec implémentation d’exigences et de conditions-cadres contraignantes)
3.2.4 Règle de contrat (simple, mais efficace) :
- les modules livrent des outputs traités comme des APIs.
- breaking output changes = major version.
- optionnel : phase de dépréciation (warning), puis removal.
3.3 Carte des artefacts : qu’existe où ?
3.3.1 Repositories (structure d’exemple)
A) Modules de base (platform-owned)
- terraform-<provider>-network
- terraform-<provider>-iam
- terraform-<provider>-logging
- terraform-<provider>-kms
B) Modules de service (shared, souvent curatés par la plateforme)
- terraform-<service>-rds
- terraform-<service>-kafka
- terraform-<service>-ecs
- terraform-<service>-oke
C) Root modules / environments (product-owned, sous Governance)
- terraform-prod-app1
- terraform-stage-app1
- terraform-prod-app2
- terraform-prod-shared
D) Policies - Controls (security-owned, intégrés à la plateforme)
- policies-opa ou policies-sentinel
- terraform-standards (tagging, naming, conventions)
E) Templates CI/CD (platform-owned)
- pipelines-terraform-template
- pipelines-policy-gates
3.4 Governance Gates : qu’est-ce qui peut se passer où ?
Le principe est le suivant : Si quelque chose est suffisamment important pour tourner en production, alors c’est suffisamment important pour être vérifié automatiquement.
Exemple : Sentinel comme Mandatory Gate (AWS - OCI)
Pour que “Policy-as-Code” ne reste pas un simple mot de PowerPoint, voici deux exemples minimaux qui font immédiatement sens en pratique : le chiffrement doit être activé - automatiquement, pas au feeling.
Exemple AWS : S3 ne doit pas être sans Default Encryption
import "tfplan/v2" as tfplan
main = rule {
all tfplan.resources.aws_s3_bucket as bucket {
bucket.applied.server_side_encryption_configuration is not null
}
}Exemple OCI : les block volumes doivent être chiffrés
import "tfplan/v2" as tfplan
main = rule {
all tfplan.resources.oci_core_volume as volume {
volume.applied.is_encrypted is true
}
}Important : Ce sont volontairement de “petites” Policies - mais elles montrent l’essentiel : la Governance ne se discute pas, elle se vérifie. Tout le reste, c’est de l’espoir avec une étiquette d’audit.
Mandatory Gates (avant chaque apply en non-dev / prod)
- terraform fmt / validate
- terraform plan en CI, plan comme artefact
- Policy-as-Code (OPA/Sentinel)
- Security Scans (p. ex. tfsec/checkov) ou équivalent
- Cost Estimation (FinOps Gate) - au minimum une indication de delta
- reviews (min. 2 eyes, dont 1 plateforme ou sécurité en cas de changements sensibles)
- apply uniquement via pipeline (pas de « laptop-apply »)
3.5 Exemple de repo layout (root modules)
Important : Les root modules sont lisibles, petits, et suivent des standards. La complexité se trouve dans les modules, pas dans le root. Cela signifie aussi : les root modules devraient autant que possible uniquement composer des modules ; des ressources ne doivent être déclarées directement qu’en exceptions justifiées.
terraform-prod-app1/
main.tf
variables.tf
outputs.tf
backend.tf
env/
prod.tfvars
stage.tfvars
README.md
3.6 Le flux end-to-end (blueprint)
 Phase 0 - Situation initiale
Phase 0 - Situation initiale
- les modules de base sont versionnés (tags)
- les root modules pinning les versions de modules (aucune référence « main branch »)
- les Policies sont activées dans le CI
Blueprint en code : les root modules consomment des modules versionnés (exemple OCI)
Voilà à quoi cela ressemble en pratique : un root module qui reste volontairement “idiot” et ne fait qu’assembler. L’intelligence se trouve dans les modules - et la stabilité dans les versions pinning.
# main.tf (Rootmodule: terraform-prod-app1)
module "network" {
source = "git::ssh://git@repo/platform/terraform-oci-network.git?ref=v2.4.0"
compartment_id = var.compartment_id
vcn_cidr = var.vcn_cidr
}
module "db" {
source = "git::ssh://git@repo/services/terraform-oci-db.git?ref=v1.3.2"
compartment_id = var.compartment_id
subnet_id = module.network.private_subnet_id
db_name = var.db_name
shape = var.db_shape
}À retenir : ce root module, on peut le reviewer. Ce root module, on peut l’auditer. Et si quelque chose casse, vous savez quelle release de module en était responsable, au lieu de vous réveiller dans un film d’horreur basé sur des diff.
Phase 1 - Changement dans le module de base (Platform Team)
Exemple : ajustement dans le module réseau (p. ex. option de subnet supplémentaire, logging par défaut, règles SG plus restrictives).
Règles :
- PR avec une change classification claire : PATCH/MINOR/MAJOR
- entrée dans le changelog + note de migration (en cas de breaking)
- les tests s’exécutent automatiquement (voir 3.7)
Output :
Tag v2.4.0 (ou v3.0.0 en cas de breaking)
Phase 2 - Release du module - distribution
Artefacts de release :
- Git tag + release notes
- documentation du module mise à jour
- « upgrade notes » pour les consumers
Mécanique de distribution :
- les root modules référencent les modules via une version (registry ou Git tag)
- optionnel : registry interne pour centraliser les validations
Phase 3 - Propagation dans les modules de service (optionnel, mais souvent pertinent)
Si les modules de service utilisent le module de base :
- PRs dans les modules de service qui adoptent la nouvelle version du module de base
- regression tests au niveau du module de service
- release tag pour les modules de service
Phase 4 - Update dans les root modules (Product Teams)
Mécanique (recommandée) :
- PR automatique (Dependency Bot / Renovate) relève la version du module :
- base-network v2.3.1 → v2.4.0
- le CI génère un plan diff
- le PR montre :
- changements de ressources
- résultats de Policy
- indications de coûts
Décision :
merge uniquement si les gates sont au vert et si le changement est compris.
Phase 5 - Pipeline apply (contrôlé)
L’apply se fait :
- d’abord en DEV / INT
- ensuite en STAGE
- ensuite en PROD
Stratégie de rollout (pour des changements critiques) :
- canary : 1-2 tenants non critiques d’abord
- ensuite rollout par vagues (wave 1-N)
Principe :
Vous ne mettez pas à l’échelle le courage - vous mettez à l’échelle la procédure.
Phase 6 - Observability - audit
Après apply :
- log/audit trail :
- qui a mergé ?
- quel plan a été applied ?
- quels Policy Checks ont tourné ?
- drift detection :
- scheduled plan (read-only) + alarme en cas de drift
- incident hooks :
- si drift / Policy Violation : ticket/alert
3.7 Blueprint de tests : qu’est-ce qui est testé, et comment ?
A) Module unit/contract tests
- input validation tests (Variable Validations)
- output contract tests (breaking detection)
- static analysis
B) Integration tests (Ephemeral Environments)
- stacks temporaires par PR
- apply + assertions (p. ex. ressources existantes, tags définis, encryption active)
- destroy à la fin (cleanup)
C) Regression tests
- contrôle de diff basé sur des snapshots pour les modules critiques
- testcases « golden » par version de module
Standard minimal :
Au minimum, un test d’apply ephemeral par release de module de base doit être effectué ; l’idéal serait des contract tests et, si nécessaire, des integration tests des modules de base via terraform test et le Terraform Testing Framework intégré (recommandé, car intégré à Terraform et standardisé) ou un testing harness équivalent. Sinon, ce n’est pas une release, c’est un pile ou face.
Exemple : terraform test comme test contract/default
Un test n’a pas besoin d’être “grand” pour être efficace. Une seule assertion vous protège déjà du classique : quelqu’un modifie discrètement un default - et des semaines plus tard, tout le monde se demande pourquoi le volume de logs et les coûts explosent soudainement.
# tests/network_defaults.tftest.hcl
run "validate_defaults" {
command = plan
assert {
condition = module.network.enable_flow_logs == true
error_message = "Flow Logs doivent être activés par défaut."
}
}Ce n’est pas un test académique. C’est une ceinture de sécurité. Et oui : si vous ne vérifiez pas ce genre de chose automatiquement, chaque release finit par être un pile ou face - simplement avec un budget de production.
3.8 Blueprint de Policy : qu’est-ce qui doit toujours être vrai ?
Exemples de Policies qui ont pratiquement toujours du sens :
- tagging/owner/costCenter obligatoires
- chiffrement by default (storage, DB, secrets)
- aucune Security Group ouverte (0.0.0.0/0) sans processus d’exception
- patterns IAM least privilege (pas de wildcards sans justification)
- restrictions de region/account/subscription
- approbation obligatoire pour les classes génératrices de coûts
Gestion des exceptions :
- exception uniquement via pull request (PR). Les exceptions doivent être marquées sous forme de code lisible par machine (p. ex. annotation/tag/policy input), sinon on retombe dans la discussion plutôt que dans le processus. Une pull request impose transparence, review par au moins une autre personne, documentation et audit trail.
- avec date d’expiration (expiry)
- avec owner
- avec ticket/justification
3.9 Blueprint de rollback et recovery
Le rollback en IaC n’est pas toujours « git revert et tout va bien ». Donc :
- prefer forward-fix en cas d’erreurs non destructives
- state operations uniquement via un processus d’urgence
- breaking changes doivent avoir un chemin de migration
- backup/versioning pour le state - les ressources critiques
- runbooks pour les failure modes fréquents (locking, throttling, provider bugs)
3.10 Résultat : ce que vous obtenez
- une gouvernance des modules scalable, sans goulot d’étranglement
- des changements reproductibles avec des responsabilités claires
- de la visibilité (plan/policy/coût) avant l’apply
- un rollout contrôlé au lieu d’un « big bang »
- une auditabilité qui ne dépend pas d’un simple appel
C’est ça, l’essentiel : Terraform @ Scale n’est pas seulement « plus de Terraform ». C’est tout autant un framework d’organisation des opérations et de change management.
3.11 Checklist pipeline blueprint : Terraform Deployment Control Flow (stage-by-stage)
Voici le cadre de contrôle compact pour les décideurs. Si ces étapes sont respectées, Terraform devient contrôlable.
Un déploiement Terraform ne peut avoir lieu que si :
- le code est valide
- le plan est transparent
- les Policies sont respectées
- les reviews ont été effectuées
- apply s’exécute exclusivement via la pipeline
- audit - drift detection sont actifs
S’il manque un seul de ces points, ce n’est pas une exploitation contrôlée.
Stage 1 - Static Validation (shift left)
L’objectif: arrêter les erreurs avant qu’elles n’impactent l’infrastructure.
- terraform fmt
- terraform validate
- Variable Validations
- linting
- static security scan
Gate:
❌ erreur → aucun merge du PR possible
Stage 2 - Plan - transparence
L’objectif: visibilité complète sur les changements.
- terraform plan dans le CI
- enregistrer l’artefact plan
- analyse de diff (add/change/destroy)
- afficher la différence de coûts
Gate:
❌ plan non vérifié → aucun merge
Stage 3 - Policy Enforcement
L’objectif: imposer la gouvernance, ne pas la discuter.
- OPA/Sentinel Policy Checks
- validation du tagging
- encryption policy
- restrictions IAM
- restrictions region/account
Gate:
❌ violation de Policy → merge bloqué
✔ exception uniquement via pull request avec justification - date d’expiration
Stage 4 - Review - approbation
L’objectif: contrôle humain en complément de l’automatisation.
- au moins 2 reviewers
- security review en cas de changements sensibles
- platform review pour les changements de modules de base
Gate:
❌ PR non approuvé → aucun apply
Stage 5 - Controlled Apply
L’objectif: déploiement reproductible, audit-able.
- apply uniquement via la pipeline
- aucun apply manuel
- déploiements de production sérialisés
- optionnel : canary / wave rollout
Stage 6 - Post-Apply Observability
L’objectif: contrôle durable après le déploiement.
- enregistrer l’audit log
- drift detection (scheduled plan)
- monitoring des mauvaises configurations
- incident hooks
4. Matrice de risques centrale : la vue d’ensemble des risques
Les risques Terraform ne naissent pas de manière isolée, ils s’additionnent.
Une matrice de risques n’est pas un élément décoratif. C’est un système de navigation : où ça va le plus probablement casser - et combien cela coûte quand ça casse ?
Échelle : probabilité d’occurrence (EW) et impact (AW) chacun de 1 (faible) à 5 (élevé).
Score = EW × AW.
Classe de risque : 1–5 faible, 6–10 moyen, 11–15 élevé, 16–25 critique.
|
ID |
Risque |
Catégorie |
Cause typique |
EW |
AW |
Score |
Indicateurs précoces |
Contrôles / contre-mesures |
Owner (typique) |
|
R1 |
Blast radius dû à des root modules « trop grands » |
Exploitation |
root modules monolithiques, absence de segmentation, absence de séparation Stacks/Workspaces |
4 |
5 |
20 |
plans volumineux (beaucoup de ressources), temps d’apply longs, rollbacks fréquents |
découper les root modules (domaines/services), stacks/envs séparés, rollouts progressifs/canaries |
Platform + Product |
|
R2 |
Version drift (provider/module/Terraform) |
Technique/exploitation |
non pinning/incohérent, toolchains différentes, absence de processus d’upgrade |
5 |
4 |
20 |
lockfiles différents, « works on my machine », plan diffs inexplicables |
version pinning + lockfile policy, flow Renovate/Dependabot, fenêtres d’upgrade définies |
Platform |
|
R3 |
Risques state (corruption, problèmes de locking, interventions manuelles) |
Exploitation |
opérations state manuelles, locking absent, applies parallèles |
3 |
5 |
15 |
conflits de lock fréquents, « force-unlock », edits de state dans les tickets |
remote state avec locking, sérialisation des applies, processus d’urgence pour les opérations state |
Platform |
|
R4 |
Policy absente ou non appliquée (policy drift) |
Sécurité/governance |
les Policies existent « comme document », mais pas comme gate ; exceptions sans date d’expiration |
4 |
5 |
20 |
findings récurrents, validations manuelles, exceptions « temporaires » qui restent |
Policy-as-Code (OPA/Sentinel) comme gate obligatoire, workflow d’exception avec expiry |
Security + Platform |
|
R5 |
Mauvaise configuration IAM (over-permissioning, privilege escalation) |
Sécurité |
réutilisation de patterns non sûrs, absence de review least privilege, ownership floue |
4 |
5 |
20 |
rôles trop larges, trop d’admins, Policies non reviewées |
modules IAM standardisés, security reviews, scans (p.ex. tfsec/checkov) + policy gates |
Security |
|
R6 |
Secrets au mauvais endroit (state, logs, variables, Git) |
Sécurité/exploitation |
secrets comme plain variables, outputs, absence de backends secrets |
3 |
5 |
15 |
secrets dans plans/logs, « sensitive » absent, fuites Git |
intégration Vault/Secret Manager, outputs sensitive, pre-commit scanning, redaction |
Security + Platform |
|
R7 |
Chaînes de dépendances - « hidden coupling » entre modules |
Technique |
cascades data sources/outputs, dépendances implicites, contracts manquants |
4 |
4 |
16 |
petit changement → grand diff, replacements inattendus, dépendances cycliques |
contracts de modules (inputs/outputs), règles de breaking change, tests + SemVer discipliné |
Platform |
|
R8 |
API limits / throttling lors de gros applies |
Exploitation/technique |
changements de masse, parallélisme, limites provider |
3 |
4 |
12 |
tempêtes de retry, timeouts, erreurs provider sporadiques |
stratégies de rate limit, batches plus petits, applies sérialisés, tuning provider |
Platform |
|
R9 |
Drift (réalité ≠ code) |
Exploitation/governance |
changements manuels dans la console cloud, absence de détection de drift |
4 |
4 |
16 |
plans inattendus, incident « fix in console », dérives progressives |
drift detection (scheduled plans), restrictions rôles/droits, policy « no clickops » en exploitation normale (break-glass manuel avec journalisation reste autorisé). |
Platform + Ops |
|
R10 |
Changements non testés (pas de regression testing pour les modules) |
Technique/exploitation |
pas de test harness, pas de gate pre-prod, pas d’étapes canary |
4 |
4 |
16 |
breaking changes uniquement en prod, taux élevé de hotfix |
tests de modules (unit/integration), ephemeral environments, pipeline gates |
Platform |
|
R11 |
Risques coûts (overprovisioning / scalabilité non maîtrisée) |
FinOps/exploitation |
budgets/guardrails absents, tailles standard absentes, pas de review |
4 |
4 |
16 |
explosions de coûts, tags manquants, ressources sans owner |
tagging comme policy, budget alerts, cost estimation dans le PR, tiers standards |
FinOps + Platform |
|
R12 |
Flou organisationnel (ownership, responsabilité, approbation) |
Organisation |
frontières plateforme/produit non clarifiées, « tout le monde peut tout faire », RACI manquant |
5 |
3 |
15 |
blocages, ping-pong de tickets, shadow repos/forks |
RACI, repo policy, responsabilités claires, interface plateforme-produit |
Management + Platform |
Condensation : top risques (score ≥ 16)
- R1, R2, R4, R5, R7, R9, R10, R11 sont les « classiques enterprise » : élevés à critiques, car ils se renforcent mutuellement.
Nous voyons en plus :
- où la governance est réellement nécessaire (R4/R5/R6).
- où une structure propre permet la mise à l’échelle (R1/R2/R7/R10).
- où l’argent part en fumée si personne ne regarde (R11).
5. Modèle RACI pour Terraform @ Scale
La pipeline définit ce qui se passe.
La matrice RACI définit qui est responsable.
Ce n’est que l’ensemble des deux qui produit un Operating Model robuste.
Rôles :
- Platform Team - standards de modules, CI/CD, gouvernance technique
- Security / organisation CISO - Policies, risk controls
- Product / Application Teams - utilisation - configuration de l’infrastructure
- FinOps / Controlling - contrôle des coûts - transparence budgétaire
Définition RACI :
- R (Responsible) - exécute
- A (Accountable) - porte la responsabilité globale
- C (Consulted) - est activement impliqué
- I (Informed) - est informé
Matrice RACI sur le flux end-to-end
|
Phase |
Platform |
Security |
Product |
FinOps |
|
développer le module de base |
R |
C |
I |
I |
|
valider le module de base (release) |
A |
C |
I |
I |
|
définir/modifier une Policy |
C |
R/A |
I |
C |
|
développer le module de service |
R |
C |
C |
I |
|
modifier le root module (changement produit) |
C |
C |
R/A |
I |
|
vérification de Policy dans le CI |
R |
A |
C |
I |
|
security review en cas de changements sensibles |
C |
R/A |
C |
I |
|
contrôle des coûts avant merge |
C |
I |
R |
A |
|
apply en DEV |
R |
I |
C |
I |
|
apply en PROD |
R |
C |
C |
I |
|
drift detection - monitoring |
R/A |
C |
I |
I |
|
approbation d’exception (policy exception) |
C |
R/A |
C |
I |
|
incident en cas de mauvaise configuration |
R |
C |
C |
I |
|
escalade des coûts |
C |
I |
C |
R/A |
Interprétation (important pour le niveau direction)
- Platform est opérationnellement responsable.
- Security est responsable des Policies.
- Product assume la responsabilité des changements fonctionnels.
- FinOps porte la responsabilité budgétaire - pas Platform.
Ce modèle évite deux erreurs classiques :
- Security devient le bloqueur du déploiement.
- la plateforme est rendue responsable des coûts ou des décisions business.
6. Implications de gouvernance exécutive
Terraform n’est pas un automatisme. L’utilisation de Terraform et d’Infrastructure-as-Code seule ne crée pas une gouvernance réellement existante. Au contraire, Terraform amplifie des méthodes et des workflows déjà en place. Et si ceux-ci ne sont pas corrects, le tir peut se retourner contre vous.
L’automatisation de l’infrastructure renforce l’impact. Dans le positif comme dans le négatif.
Prenez par exemple une entreprise de taille moyenne avec 25 équipes IT, dont chacune vit ses propres habitudes et façons de travailler - le résultat serait, malgré Terraform, un enchevêtrement impénétrable de modules, pipelines et dépendances non alignés. Cela ne sert à rien si chaque équipe est dans son propre bateau et rame. Vous, en tant que dirigeant, devez vous assurer que tous avancent dans la même direction, au même rythme, avec des pagaies identiques. Avec l’IaC, ces équipes dérivent sinon beaucoup plus vite et plus directement les unes des autres et ne forment plus un ensemble harmonieux.
Pour les CIO et CISO, Terraform @ Scale signifie au premier abord :
- l’infrastructure devient du code
- le code devient pertinent pour la gouvernance
- la gouvernance devient automatisable
Mesures supplémentaires recommandées :
- mise en place d’une équipe plateforme dédiée
- introduction de mécanismes Policy-as-Code obligatoires
- repository de modules centralisé
- politiques de versioning définies
- gates CI/CD obligatoires
- revues d’architecture régulières
7. Conclusion - perspectives
Terraform en environnement enterprise n’est pas un sujet d’outil.
C’est avant tout un modèle d’architecture et d’organisation.
Celui qui introduit Terraform sans Operating Model met à l’échelle l’incertitude.
Celui qui opère Terraform avec une gouvernance claire met à l’échelle la stabilité.
Prochaines étapes d’évolution :
- Infrastructure Testing Frameworks
- Design for Failure Patterns
- modèles de maturité d’équipe plateforme
- intégration avec des service catalogs
- rapports de conformité automatisés
Terraform @ Scale signifie :
- contrôle sans blocage.
- standardisation sans perte d’innovation.
- vitesse sans perte de contrôle.
Et c’est précisément là que se décide si l’infrastructure reste un risque, ou devient un avantage concurrentiel.

