















Terraform @ Scale is not a question of tool usage. It is a question of the operating model.
Without a structured governance model, the following emerge:
- uncontrolled module forks
- diverging security standards
- unclear responsibilities
- increasing operational risks
- regulatory attack surfaces
- significant financial impact due to misconfigurations
This final article of our series consolidates:
- a comprehensive Terraform operating model
- governance and structural principles
- organizational responsibilities
- CI/CD and policy integration
- enterprise-level risk aggregation
- a complete blueprint for Terraform @ Scale
Target audience: CIO, CISO, Head of Platform Engineering, Cloud Architects.
Operational Guide for Decision-Makers and Architects
1. The Terraform Operating Model (Reference Architecture)
Terraform does not scale by adding more code. It scales through a clean structure.
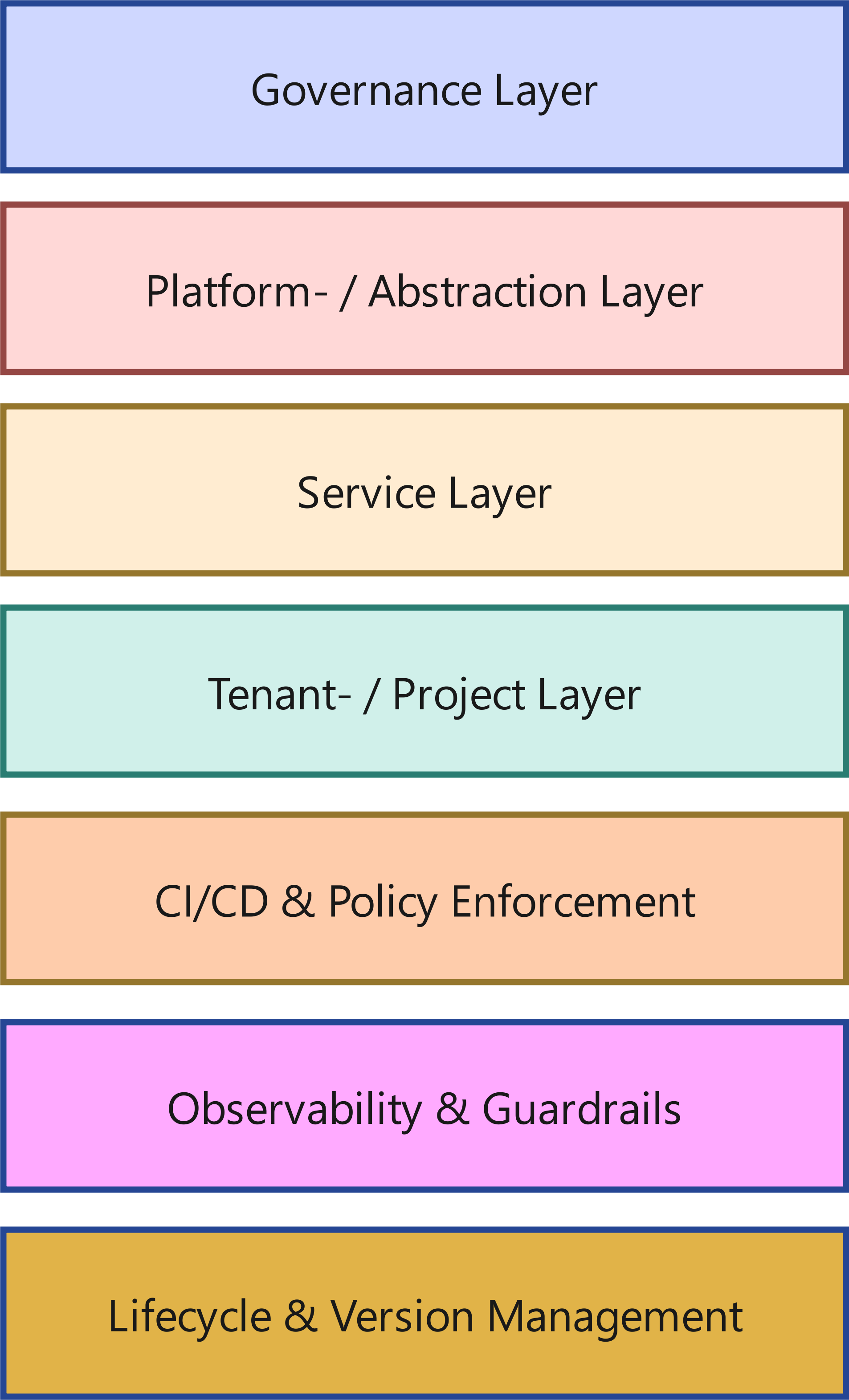 A resilient operating model consists of clearly separated layers:
A resilient operating model consists of clearly separated layers:
1.1 Governance Layer
- Policy-as-Code (Sentinel, OPA)
- compliance rules
- naming standards
- security requirements
- cost control mechanisms
1.2 Platform / Abstraction Layer
- base modules
- network standards
- IAM patterns
- logging & monitoring foundations
- security controls
1.3 Service Layer
- reusable service modules
- application-oriented infrastructure
- database patterns
- messaging patterns
1.4 Tenant / Project Layer
- product or project configuration
- environment-specific parameters
- root modules
1.5 CI/CD & Policy Enforcement
- automated pipelines
- mandatory reviews
- plan validation
- policy checks before apply
1.6 Observability & Guardrails
- drift detection
- deployment monitoring
- audit trails
- alerting in case of policy violations
1.7 Lifecycle & Version Management
- module versioning
- semantic versioning
- deprecation strategies
- migration paths
The crucial point: These layers are deliberately separated - both technically and organizationally.
2. How to Orchestrate Terraform at the Enterprise Level
Terraform in an enterprise context is not a collection of repositories.
It is an orchestrated system.
2.1 GitOps Structure
Recommended structure:
- base module repositories
- service module repositories
- environment / root repositories
- central policy repositories
Branch strategies:
- protected main branches
- pull request reviews
- version tags for production releases
2.2 Roles & Responsibilities
- platform team: base modules & governance
- product teams: service modules & root modules
- security: policy definition & review
- FinOps: cost control & reporting
Without clear separation of roles, chaos emerges.
With clear separation of roles, scalability emerges.
2.3 Workspaces / Stacks / Environments
- clear separation between Dev / Stage / Prod
- no implicit environment switches
- no manual state manipulation
2.4 Base Modules vs. Service Modules vs. Root Modules
- base modules: technical standards
- service modules: reusable services
- root modules: concrete implementation
This separation significantly reduces the blast radius.
2.5 Migration Processes
- version upgrade strategies
- canary deployments
- phased rollouts
- regression testing before propagation
2.6 Review and Automation Processes
- mandatory pipelines
- policy checks
- automated tests
- no direct apply permissions in production
3. Blueprint: Terraform @ Scale in Practice
This blueprint shows an end-to-end reference flow that works reliably in an enterprise context: from the module change to an auditable rollout across multiple product teams - including governance, testing, propagation, and observability.
3.1 Target State in One Sentence
The platform team delivers versioned base modules + guardrails; product teams consume them via clearly defined root modules; CI/CD enforces tests, policy, and controlled apply; drift and audit run continuously alongside.
3.2 Module Types & Contracts
3.2.1 Base Modules
- define technical standards (network, IAM baseline, logging, encryption defaults)
- may introduce breaking changes - but only in a controlled manner and rarely
- are SemVer strict: MAJOR.MINOR.PATCH
3.2.2 Service Modules
- encapsulate recurring services
- use base modules
- have stable interfaces (inputs/outputs)
3.2.3 Root Modules
- "assemblies": combine service and base modules for a specific environment
- contain no logic that belongs in modules
- are the place where product / environment-specific parameterization happens (so-called "T-shirt sizes" with implementation of mandatory requirements and guardrails)
3.2.4 Contract Rule (simple, but effective):
- Modules provide outputs that are treated like APIs.
- Breaking output changes = major version.
- Optional: deprecation phase (warning), then removal.
3.3 Artifact Map: What Exists Where?
3.3.1 Repositories (Example Structure)
A) Base Modules (Platform-owned)
- terraform-<provider>-network
- terraform-<provider>-iam
- terraform-<provider>-logging
- terraform-<provider>-kms
B) Service Modules (shared, often platform-curated)
- terraform-<service>-rds
- terraform-<service>-kafka
- terraform-<service>-ecs
- terraform-<service>-oke
C) Root Modules / Environments (Product-owned, under governance)
- terraform-prod-app1
- terraform-stage-app1
- terraform-prod-app2
- terraform-prod-shared
D) Policies & Controls (Security-owned, platform integrated)
- policies-opa or policies-sentinel
- terraform-standards (tagging, naming, conventions)
E) CI/CD Templates (Platform-owned)
- pipelines-terraform-template
- pipelines-policy-gates
3.4 Governance Gates: What Is Allowed Where?
The principle applies: If something is important enough to run in production, it is important enough to be checked automatically.
Example: Sentinel as a Mandatory Gate (AWS & OCI)
So that "Policy-as-Code" does not remain just a PowerPoint buzzword, here are two minimal examples that immediately make sense in practice: encryption must be enabled - automatically, not based on gut feeling.
AWS Example: S3 Must Not Be Without Default Encryption
import "tfplan/v2" as tfplan
main = rule {
all tfplan.resources.aws_s3_bucket as bucket {
bucket.applied.server_side_encryption_configuration is not null
}
}OCI Example: Block Volumes Must Be Encrypted
import "tfplan/v2" as tfplan
main = rule {
all tfplan.resources.oci_core_volume as volume {
volume.applied.is_encrypted is true
}
}Important: These are intentionally "small" policies - but they make the point: governance is not debated, it is checked. Everything else is hope with an audit label.
Mandatory Gates (Before Every Apply in Non-Dev / Prod)
- terraform fmt / validate
- terraform plan in CI, plan as an artifact
- Policy-as-Code (OPA/Sentinel)
- security scans (e. g. tfsec/checkov) or equivalent
- cost estimation (FinOps gate) - at least delta indication
- reviews (min. 2 eyes, including 1 platform or security for sensitive changes)
- apply only via pipeline (no "laptop apply")
3.5 Example Repo Layout (Root Modules)
Important: Root modules are readable, small, and follow standards. The complexity lives in modules, not in the root. This also means: root modules should, as far as possible, only compose modules; resources should only be declared directly in justified exceptions.
terraform-prod-app1/
main.tf
variables.tf
outputs.tf
backend.tf
env/
prod.tfvars
stage.tfvars
README.md
3.6 The End-to-End Flow (Blueprint)
 Phase 0 - Initial Situation
Phase 0 - Initial Situation
- base modules are versioned (tags)
- root modules pin module versions (no "main branch" references)
- policies are enabled in CI
Blueprint in Code: Root Modules Consume Versioned Modules (OCI Example)
This is what it looks like in practice: a root module that deliberately stays "dumb" and only composes. The intelligence lives in the modules - and the stability in the pinned versions.
# main.tf (Rootmodule: terraform-prod-app1)
module "network" {
source = "git::ssh://git@repo/platform/terraform-oci-network.git?ref=v2.4.0"
compartment_id = var.compartment_id
vcn_cidr = var.vcn_cidr
}
module "db" {
source = "git::ssh://git@repo/services/terraform-oci-db.git?ref=v1.3.2"
compartment_id = var.compartment_id
subnet_id = module.network.private_subnet_id
db_name = var.db_name
shape = var.db_shape
}Note: This root module can be reviewed. This root module can be audited. And if something breaks, you know which module release was responsible, instead of waking up in a diff-based horror movie.
Phase 1 - Change in the Base Module (Platform Team)
Example: Change in the network module (e. g. additional subnet option, logging default, more restrictive SG rules).
Rules:
- PR with clear change classification: PATCH/MINOR/MAJOR
- changelog entry + migration note (if breaking)
- tests run automatically (see 3.7)
Output:
Tag v2.4.0 (or v3.0.0 if breaking)
Phase 2 - Module Release & Distribution
Release artifacts:
- Git tag + release notes
- module documentation updated
- "upgrade notes" for consumers
Distribution mechanics:
- root modules reference modules via version (registry or Git tag)
- optional: internal registry to centralize approvals
Phase 3 - Propagation into Service Modules (optional, but often useful)
If service modules use the base module:
- PRs in service modules that adopt the new base module version
- regression tests at the service module level
- release tag for service modules
Phase 4 - Update in Root Modules (Product Teams)
Mechanics (recommended):
- automated PR (dependency bot / Renovate) bumps the module version:
- base-network v2.3.1 → v2.4.0
- CI produces a plan diff
- PR shows:
- resource changes
- policy results
- cost indications
Decision:
Merge only if gates are green and the change is understood.
Phase 5 - Pipeline Apply (controlled)
Apply happens:
- first in DEV / INT
- then STAGE
- then PROD
Rollout strategy (for critical changes):
- canary: 1-2 non-critical tenants first
- then wave rollout (wave 1-N)
Principle:
You are not scaling courage - you are scaling the procedure.
Phase 6 - Observability & Audit
After apply:
- log/audit trail:
- Who merged?
- Which plan was applied?
- Which policy checks ran?
- drift detection:
- scheduled plan (read-only) + alert on drift
- incident hooks:
- if drift / policy violation: ticket/alert
3.7 Testing Blueprint: What Is Tested How?
A) Module Unit/Contract Tests
- input validation tests (variable validations)
- output contract tests (breaking detection)
- static analysis
B) Integration Tests (Ephemeral Environments)
- temporary stacks per PR
- apply + assertions (e. g. resources exist, tags set, encryption enabled)
- destroy at the end (cleanup)
C) Regression Tests
- snapshot-based diff verification for critical modules
- "golden" test cases per module version
Minimum standard:
At least one ephemeral apply test per base module release must be executed, ideally contract tests and, if applicable, integration tests of the base modules using terraform test and the integrated Terraform Testing Framework (recommended because it is integrated and standardized in Terraform) or an equivalent testing harness. Otherwise it is not a release, it is a coin toss.
Example: terraform test as a Contract/Default Test
A test does not have to be "large" to be effective. Even a single assertion protects you from the classic: someone silently flips a default - and weeks later everyone wonders why log volume and costs suddenly explode.
# tests/network_defaults.tftest.hcl
run "validate_defaults" {
command = plan
assert {
condition = module.network.enable_flow_logs == true
error_message = "Flow Logs must be enabled by default."
}
}This is not an academic test. This is a seat belt. And yes: If you do not check something like this automatically, every release ultimately becomes a coin toss - just with a production budget.
3.8 Policy Blueprint: What Must Always Be True?
Examples of policies that almost always make sense in practice:
- mandatory tagging / owner / cost center
- encryption by default (storage, DB, secrets)
- no open security groups (0.0.0.0/0) without an exception process
- IAM least privilege patterns (no wildcards without justification)
- region / account / subscription restrictions
- approval required for cost-driving classes
Exception handling:
- exceptions only via pull request (PR). Exceptions must be marked as machine-readable code (e. g. annotation/tag/policy input), otherwise it becomes discussion again instead of process. A pull request enforces transparency, review by at least one other person, documentation, and an audit trail.
- with expiry date (expiry)
- with owner
- with ticket / justification
3.9 Rollback and Recovery Blueprint
Rollback in IaC is not always "git revert and everything is fine". Therefore:
- Prefer forward-fix for non-destructive errors
- State operations only with an emergency process
- Breaking changes must have a migration path
- Backup/versioning for state & critical resources
- Runbooks for common failure modes (locking, throttling, provider bugs)
3.10 Result: What You Achieve with This
- scalable module governance without bottlenecks
- reproducible changes with clear responsibilities
- visibility (plan/policy/cost) before apply
- controlled rollout instead of "big bang"
- auditability that does not happen by shouting across the room
That is the point: Terraform @ Scale is not just "more Terraform". It is also a framework for operational organization and change management.
3.11 Pipeline Blueprint Checklist: Terraform Deployment Control Flow (Stage-by-Stage)
This is the compact control framework for decision-makers. If these steps are followed, Terraform is controllable.
A Terraform deployment may only take place if:
- code is valid
- plan is transparent
- policies are met
- reviews have been completed
- apply runs exclusively via pipeline
- audit & drift detection are active
If any of these points is missing, it is not controlled operations.
Stage 1 - Static Validation (Shift Left)
Objective: stop errors before infrastructure is affected.
- terraform fmt
- terraform validate
- variable validations
- linting
- static security scan
Gate:
❌ errors - no PR merge possible
Stage 2 - Plan & Transparency
Objective: full visibility into changes.
- terraform plan in CI
- store plan artifact
- diff analysis (add/change/destroy)
- show cost delta
Gate:
❌ unreviewed plan - no merge
Stage 3 - Policy Enforcement
Objective: enforce governance, do not debate it.
- OPA/Sentinel policy checks
- tagging validation
- encryption policy
- IAM restrictions
- region / account restrictions
Gate:
❌ policy violation - merge blocked
✔ exception only via pull request with justification & expiry date
Stage 4 - Review & Approval
Objective: human control as a complement to automation.
- at least 2 reviewers
- security review for sensitive changes
- platform review for base module changes
Gate:
❌ no approved PR - no apply
Stage 5 - Controlled Apply
Objective: reproducible, auditable deployment.
- apply only via pipeline
- no manual apply
- serialized production deployments
- optional: canary / wave rollout
Stage 6 - Post-Apply Observability
Objective: sustainable control after deployment.
- store audit log
- drift detection (scheduled plan)
- monitoring for misconfiguration
- incident hooks
4. Central Risk Matrix: The Overall Risk Picture
Terraform risks do not emerge in isolation, they add up.
A risk matrix is not a decorative element. It is a navigation device: where is it most likely to blow up - and what does it cost if it blows up?
Scale: probability of occurrence (PO) and impact (IM) each 1 (low) to 5 (high).
Score = PO × IM.
Risk class: 1-5 low, 6-10 medium, 11-15 high, 16-25 critical.
|
ID |
Risk |
Category |
Typical cause |
PO |
IM |
Score |
Early indicators |
Controls / countermeasures |
Owner (typical) |
|
R1 |
Blast radius due to "too large" root modules |
Operations |
monolithic root modules, missing segmentation, missing stack/workspace separation |
4 |
5 |
20 |
large plans (many resources), long apply times, frequent rollbacks |
split root modules (domains/services), separate stacks/environments, progressive rollouts/canaries |
Platform + Product |
|
R2 |
Version drift (provider/module/Terraform) |
Technology/Operations |
unpinned/inconsistent, different toolchains, missing upgrade process |
5 |
4 |
20 |
different lockfiles, "works on my machine", inexplicable plan diffs |
version pinning + lockfile policy, Renovate/Dependabot flow, defined upgrade windows |
Platform |
|
R3 |
State risks (corruption, locking issues, manual interventions) |
Operations |
manual state operations, missing locking, parallel applies |
3 |
5 |
15 |
frequent lock conflicts, "force-unlock", state edits in tickets |
remote state with locking, apply serialization, emergency process for state operations |
Platform |
|
R4 |
Policy is missing or not enforced (policy drift) |
Security/Governance |
policies exist "as a document" but not as a gate, exceptions without expiry date |
4 |
5 |
20 |
recurring findings, manual approvals, "temporary" exceptions remain |
Policy-as-Code (OPA/Sentinel) as a mandatory gate, exception workflow with expiry |
Security + Platform |
|
R5 |
IAM misconfiguration (over-permissioning, privilege escalation) |
Security |
reuse of insecure patterns, missing least privilege review, unclear ownership |
4 |
5 |
20 |
broad roles, too many admins, unreviewed policies |
standardized IAM modules, security reviews, scans (e.g. tfsec/checkov) + policy gates |
Security |
|
R6 |
Secrets in the wrong place (state, logs, variables, Git) |
Security/Operations |
secrets as plain variables, outputs, missing secret backends |
3 |
5 |
15 |
secrets in plans/logs, missing "sensitive", Git leaks |
Vault/secret manager integration, sensitive outputs, pre-commit scanning, redaction |
Security + Platform |
|
R7 |
Dependency chains & "hidden coupling" between modules |
Technology |
data source/output cascades, implicit dependencies, missing contracts |
4 |
4 |
16 |
small change → large diff, unexpected replacements, cyclic dependencies |
module contracts (inputs/outputs), breaking change rules, tests + SemVer discipline |
Platform |
|
R8 |
API limits / throttling with large applies |
Operations/Technology |
mass changes, parallelism, provider limits |
3 |
4 |
12 |
retry storms, timeouts, sporadic provider errors |
rate limit strategies, smaller batches, serialized applies, provider tuning |
Platform |
|
R9 |
Drift (reality ≠ code) |
Operations/Governance |
manual changes in the cloud console, missing drift detection |
4 |
4 |
16 |
unexpected plans, incident "fix in console", creeping deviations |
drift detection (scheduled plans), role/permission restrictions, "no ClickOps" policy in normal operations (manual break-glass with logging remains permitted). |
Platform + Ops |
|
R10 |
Untested changes (no regression testing for modules) |
Technology/Operations |
no test harness, no pre-prod gate, no canary stages |
4 |
4 |
16 |
breaking changes only discovered in prod, high hotfix rate |
module tests (unit/integration), ephemeral environments, pipeline gates |
Platform |
|
R11 |
Cost risks (overprovisioning / uncontrolled scaling) |
FinOps/Operations |
missing budgets/guardrails, missing standard sizes, no review |
4 |
4 |
16 |
cost explosions, missing tags, resources without an owner |
tagging as policy, budget alerts, cost estimation in the PR, standard tiers |
FinOps + Platform |
|
R12 |
Organizational ambiguity (ownership, responsibility, approval) |
Organization |
unclear platform/product boundaries, "everyone can do everything", missing RACI |
5 |
3 |
15 |
blockers, ticket ping-pong, shadow repos/forks |
RACI, repo policy, clear responsibilities, platform-product interface |
Management + Platform |
Condensed: Top Risks (Score ≥ 16)
- R1, R2, R4, R5, R7, R9, R10, R11 are the typical "enterprise classics": high to critical because they reinforce each other.
We also see:
- where governance is truly necessary (R4/R5/R6).
- where a clean structure enables scaling (R1/R2/R7/R10).
- where money burns when nobody is watching (R11).
5. RACI Model for Terraform @ Scale
The pipeline defines what happens.
The RACI matrix defines who is accountable.
Only both together result in a resilient operating model.
Roles:
- Platform Team - module standards, CI/CD, technical governance
- Security / CISO Organization - policies, risk controls
- Product / Application Teams - use & configuration of infrastructure
- FinOps / Controlling - cost control & budget transparency
RACI definition:
- R (Responsible) - executes
- A (Accountable) - holds overall accountability
- C (Consulted) - is actively involved
- I (Informed) - is informed
RACI Matrix Across the End-to-End Flow
|
Phase |
Platform |
Security |
Product |
FinOps |
|
Develop base module |
R |
C |
I |
I |
|
Approve base module (release) |
A |
C |
I |
I |
|
Define/change policy |
C |
R/A |
I |
C |
|
Develop service module |
R |
C |
C |
I |
|
Change root module (product change) |
C |
C |
R/A |
I |
|
Policy check in CI |
R |
A |
C |
I |
|
Security review for sensitive changes |
C |
R/A |
C |
I |
|
Cost check before merge |
C |
I |
R |
A |
|
Apply in DEV |
R |
I |
C |
I |
|
Apply in PROD |
R |
C |
C |
I |
|
Drift detection & monitoring |
R/A |
C |
I |
I |
|
Exception approval (policy exception) |
C |
R/A |
C |
I |
|
Incident due to misconfiguration |
R |
C |
C |
I |
|
Cost escalation |
C |
I |
C |
R/A |
Interpretation (Important for the Leadership Level)
- Platform is operationally responsible.
- Security is accountable for policy.
- Product is accountable for functional changes.
- FinOps holds budget accountability - not platform.
This model prevents two classic mistakes:
- Security becomes the deployment blocker.
- Platform is held responsible for costs or business decisions.
6. Executive Governance Implications
Terraform is not self-running. Using Terraform and Infrastructure-as-Code alone does not create real governance. Instead, Terraform amplifies existing methods and workflows. And if those are wrong, it can backfire.
Infrastructure automation amplifies the effect. Both positively and negatively.
Take, for example, a mid-sized company with 25 IT teams, each living its own habits and ways of working - the result would be, even with Terraform, an impenetrable mesh of uncoordinated modules, pipelines, and dependencies. It does not help if each team sits in its own boat and rows. As a leader, you must ensure that everyone is moving in the same direction and at the same cadence, with identical paddles. With IaC, these teams otherwise drift away from each other much faster and more linearly, and no longer form a harmonious whole.
For CIOs and CISOs, Terraform @ Scale at first glance means:
- infrastructure becomes code
- code becomes governance-relevant
- governance becomes automatable
Recommended additional measures:
- build a dedicated platform team
- introduce mandatory policy-as-code mechanisms
- centralized module repository
- defined versioning guidelines
- mandatory CI/CD gates
- regular architecture reviews
7. Conclusion & Outlook
Terraform in an enterprise environment is not a tool topic.
It is an architecture and organizational model.
Those who introduce Terraform without an operating model scale uncertainty.
Those who operate Terraform with clear governance scale stability.
Next expansion stages:
- infrastructure testing frameworks
- design for failure patterns
- platform team maturity models
- integration with service catalogs
- automated compliance reports
Terraform @ Scale means:
- control without blockage.
- standardization without loss of innovation.
- speed without loss of control.
And that is exactly where it is decided whether infrastructure remains a risk, or becomes a competitive advantage.

