










Il est 14h30 un mardi après-midi ordinaire. L’équipe DevOps d’un prestataire de services financiers suisse lance comme à l’accoutumée sa pipeline Terraform pour le test mensuel de reprise après sinistre. 300 machines virtuelles, 150 backends de Load Balancer, 500 entrées DNS et d’innombrables règles réseau doivent être provisionnés dans la région de secours.
Après 5 minutes, la pipeline s’interrompt. HTTP 429 : Too Many Requests.
L’équipe passe ensuite 3 heures à nettoyer manuellement les ressources partiellement provisionnées, tandis que la direction regarde nerveusement l’horloge.
Le test de DR a échoué avant même d’avoir commencé.
Lire la suite : Terraform @ Scale - Partie 5a : comprendre les limites API

Durée de validité des certificats TLS drastiquement réduite : les décideurs IT doivent AGIR MAINTENANT !
À partir de mars 2026, la durée maximale de validité des certificats serveur sera d’abord réduite à 200 jours, puis progressivement à 100 et enfin à 47 jours.
Les entreprises sans stratégie de PKI Enterprise s’exposent à des goulots d’étranglement opérationnels et à des problèmes de conformité visibles pour les clients.
Les faits - Décision du CA/Browser Forum
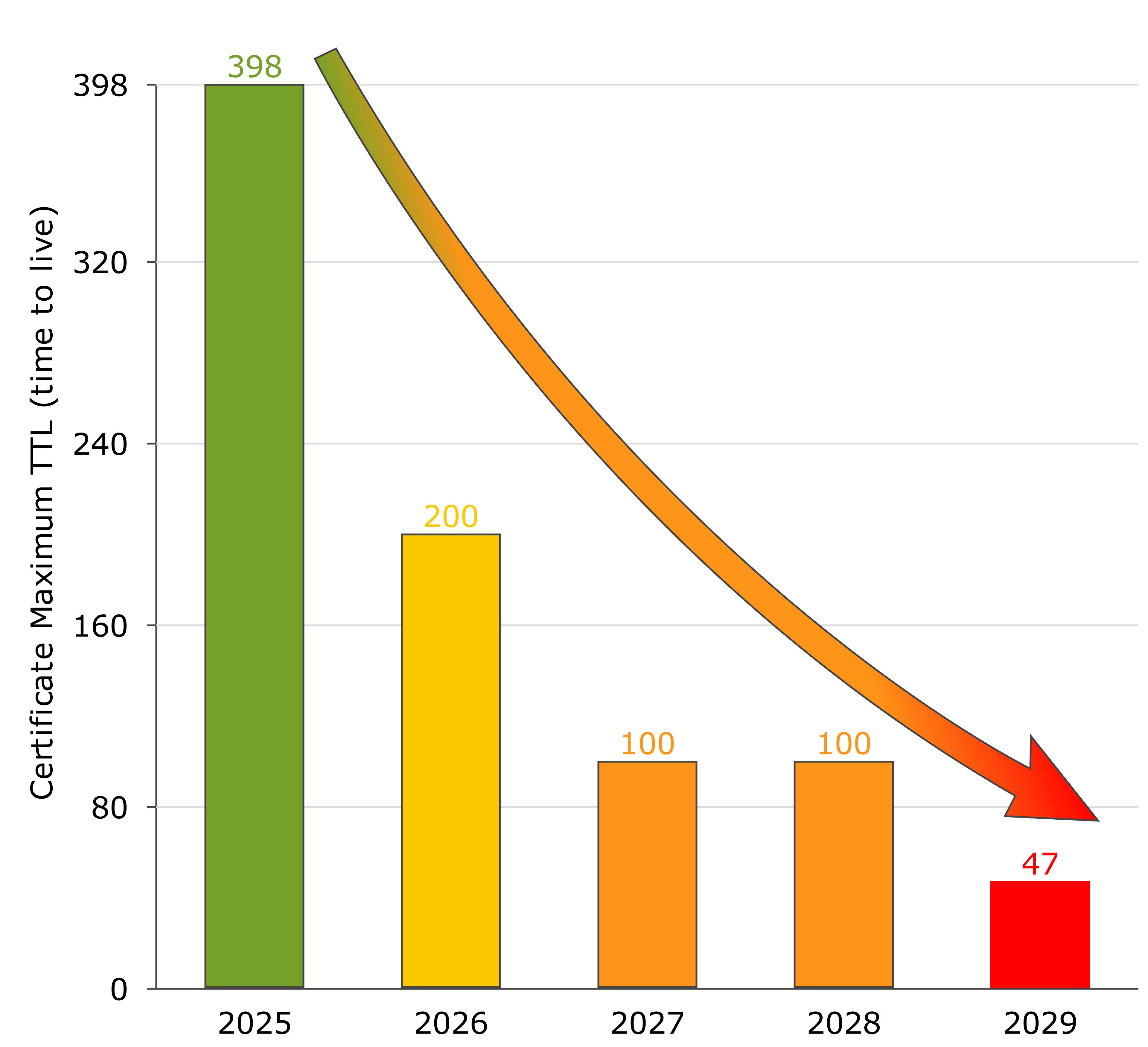 Le CA/Browser Forum a adopté le Ballot SC‑081 v3 le 11 avril 2025, établissant un calendrier contraignant de réduction des durées de validité :
Le CA/Browser Forum a adopté le Ballot SC‑081 v3 le 11 avril 2025, établissant un calendrier contraignant de réduction des durées de validité :
| Date d’entrée en vigueur | Durée maximale | Fréquence de renouvellement |
|---|---|---|
| 15 mars 2026 | 200 jours | ~2× par an |
| 15 mars 2027 | 100 jours | ~4× par an |
| 15 mars 2029 | 47 jours | ~8× par an |
Tous les principaux éditeurs de navigateurs ont annoncé qu’ils bloqueraient les certificats plus longs à partir de ces dates. (CA/Browser Forum, Business Wire)
Cette décision est définitive - aucun délai de grâce ne sera accordé.
Impact métier - Ce que cela implique pour votre entreprise
Charge opérationnelle en forte augmentation
La réduction des intervalles multiplie les efforts requis par vos équipes :
- Aujourd’hui : 1 renouvellement/an
- 2026 : 2 renouvellements/an
- 2027 : 4 renouvellements/an
- 2029 : 8 renouvellements/an
Imaginez maintenant que vous utilisiez une centaine de certificats TLS pour vos serveurs web publics, la sécurisation de vos services internes et de la communication interne. Pour les entreprises de taille moyenne à grande, cela représente rapidement plusieurs milliers de certificats individuels.
Les temps où l’on commandait et installait manuellement de nouveaux certificats sont bel et bien révolus.
Sans automatisation, vos ingénieurs passeraient une grande partie de leur temps à l’acquisition, à la distribution et au contrôle des certificats.
Risque d’indisponibilité lié à l’erreur humaine
Déjà aujourd’hui, selon une étude du Ponemon Institute, 73 % des interruptions non planifiées sont dues à des certificats expirés ou mal gérés. (mcpmag.com)
Multiplier par huit les renouvellements augmente mécaniquement le risque qu’un certificat passe inaperçu en production.
Complexité de conformité et d’audit
Chaque réduction de durée impose des preuves supplémentaires – en particulier dans les secteurs réglementés. Le suivi manuel via des tableaux ou des scripts ad hoc n’est pas scalable.
Pourquoi les approches standard sont insuffisantes
| Approche | Avantages | Facteurs limitants |
|---|---|---|
| Let’s Encrypt | Gratuit, automatisation via ACME | Aucun modèle centralisé de politiques ou de rôles, absence de journaux d’audit, pas de CAs privées |
| Services PKI Cloud | Déploiement rapide | Verrouillage fournisseur, obstacles au multi-cloud, gouvernance limitée |
| CAs traditionnelles | Ancres de confiance éprouvées | Processus de commande manuels, absence d’API, problèmes de passage à l’échelle |
Notre offre - La réponse Enterprise à la réduction des durées de certificats
 Nous mettons en œuvre la gestion de certificats et la PKI sur la base de HashiCorp Vault (connu à partir du T4/2025 également sous le nom IBM Vault). Que vous choisissiez la version gratuite (Open Source) ou l’édition Enterprise dépend entièrement de vos besoins concrets.
Nous mettons en œuvre la gestion de certificats et la PKI sur la base de HashiCorp Vault (connu à partir du T4/2025 également sous le nom IBM Vault). Que vous choisissiez la version gratuite (Open Source) ou l’édition Enterprise dépend entièrement de vos besoins concrets.
Gouvernance PKI centralisée
Vault agit comme une Certificate Authority interne et impose des politiques cohérentes sur tous les environnements – On‑Premise, AWS, OCI ou multi‑cloud.
Automatisation sans verrouillage fournisseur
L’approche API-first permet une intégration CI/CD de bout en bout et élimine les interventions humaines lors de l’émission, du renouvellement ou de la révocation.
Audit-Trails prêts pour la conformité
Chaque étape – de la génération de clés à la révocation – est consignée de façon immuable. La conformité aux audits est ainsi assurée par défaut.
ROI mesurable
Les retours d’expérience avec HashiCorp montrent une réduction de plus de 60 % de la charge opérationnelle dans des environnements comparables. Plus les durées de validité sont courtes, plus l’effet est important.
Options stratégiques
| Option | Risque | Adapté à |
|---|---|---|
| Maintenir le statu quo | Risque maximal : surcharge humaine, indisponibilités, findings d’audit | Environnements limités avec peu de certificats externes |
| Service PKI Cloud | Moyen : verrouillage fournisseur, stratégie multi‑cloud limitée | Workloads mono‑cloud sans exigences réglementaires strictes |
| PKI Enterprise avec HashiCorp Vault | Faible : contrôle total, évolutif, traçable | Entreprises avec applications critiques et feuille de route multi‑cloud |
Réflexions sur le calendrier et le budget
- Sécurisez votre budget dès 2025 – La première réduction intervient en milieu d’exercice 2026.
- Prévoir 6 à 9 mois pour l’introduction des processus et outils.
- Phase pilote : démarrez avec des services moins critiques, collectez des KPIs, puis passez à l’échelle.
Pourquoi ICT.technology est votre Trusted Advisor

- Partenaire HashiCorp avec consultants certifiés Vault
- Droit & réglementation : expertise approfondie dans la finance, la santé et l’industrie
- Méthodologie End‑to‑End : du conseil stratégique à l’implémentation IaC (Terraform‑Stacks, Ansible, OCI, AWS) jusqu’à l’exploitation PKI managée
- Modèles éprouvés de réussite issus de nombreux projets
Étapes suivantes
Prêt pour la transformation PKI ?
Réservez un rendez‑vous pour une évaluation sans engagement et une stratégie Vault sur mesure.
Nous recommandons ensuite l’approche suivante :
- Assessment PKI : établir l’inventaire et le niveau de maturité actuel
- Définir l’architecture cible : On‑Premise, Cloud ou hybride
- Concevoir une stratégie PKI : adaptée à vos besoins spécifiques
- Pilote / Proof‑of‑Concept avec Vault : à faible risque, mesurable, scalable
- Déploiement : migration progressive des systèmes critiques
Sources
- CA/Browser Forum, Ballot SC‑081v3, 11 avril 2025 (CA/Browser Forum)
- BusinessWire : « CA/Browser Forum Passes Ballot to Reduce SSL/TLS Certificates to 47 Day Maximum Term », 14 avril 2025 (Business Wire)
- Ponemon Institute : « Key and Certificate Errors Survey », 2020 (73 % d’indisponibilités) (mcpmag.com)
- HashiCorp Case Study « Running HashiCorp with HashiCorp », 2021 – plus de 60 % de réduction des coûts (HashiCorp - téléchargement PDF)

Dans la dernière partie de cette série, nous avons montré comment des Data Sources apparemment inoffensives dans les modules Terraform peuvent devenir un véritable problème de performance. Des exécutions de terraform plan durant plusieurs minutes, des pipelines instables et des effets incontrôlables de limitation d’API en étaient les conséquences.
Mais comment éviter élégamment et durablement ce piège de mise à l’échelle ?
Dans cette partie, nous présentons des modèles d’architecture éprouvés vous permettant de centraliser les Data Sources, de les injecter avec parcimonie en termes de ressources, et ainsi de garantir des exécutions Terraform rapides, stables et prévisibles, même avec des centaines d’instances de modules.
Au programme : trois stratégies de solution évolutives, un guide pas-à-pas éprouvé en pratique et une checklist de bonnes pratiques pour des modules d’infrastructure prêts pour la production.
Lire la suite : Terraform @ Scale - Partie 4b : Bonnes pratiques pour des Data Sources évolutives

Les Data Sources de Terraform sont un moyen populaire de renseigner dynamiquement des variables avec des valeurs réellement existantes de l’environnement cloud concerné. Mais leur utilisation dans des infrastructures dynamiques demande une certaine prévoyance. Il suffit par exemple d’un innocent data.oci_identity_availability_domains dans un module - et soudain, chaque exécution de terraform plan prend des minutes au lieu de secondes. Car 100 instances de module signifient 100 appels API, et votre fournisseur cloud commence à appliquer un throttling. Bienvenue dans le monde de l’amplification API involontaire via les Data Sources.
Dans cet article, je vous montre pourquoi les Data Sources dans les modules Terraform peuvent poser un problème de mise à l’échelle.
Lire la suite : Terraform @ Scale - Partie 4a : Les Data Sources sont dangereuses !

Même l’architecture d’infrastructure la plus sophistiquée ne peut pas prévenir toutes les erreurs. C’est pourquoi il est essentiel de surveiller de manière proactive les opérations Terraform - en particulier celles qui peuvent avoir des conséquences potentiellement destructrices. L’objectif est de détecter précocement les modifications critiques et de déclencher automatiquement des alertes, avant qu’un rayon d’impact incontrôlé ne survienne.
Oui, bien sûr - votre ingénieur système vous rappellera sans doute que Terraform affiche l’intégralité du plan avant l’exécution d’un apply et qu’il faut encore confirmer manuellement l’exécution par la saisie de "yes".
Ce que votre ingénieur ne vous dit pas : il ne lit en réalité pas le plan avant de le lancer.
« Ça ira. »
Plus d'articles...
- HashiCorp Vault Deep Dive – Partie 2b : Travail pratique avec le Key/Value Secrets Engine
- Terraform @Scale - Partie 3b : Stratégies de récupération après un Blast Radius
- Plongée approfondie dans HashiCorp Vault – Partie 2a : Activer la Key/Value Secrets Engine
- Terraform @ Scale - Partie 3a: Gestion du Blast Radius